1. TRANSPORT LAYER
TCP
특징
reliable (신뢰 가능한, error & loss 재전송으로 해결 가능)
connection-oriented (연결 지향)
in-order (패킷 순서 보장)
flow control (흐름 제어)
congestion control (혼잡 제어)
데이터 전송 방식
circuit switching (no sharing)
전화에서 사용되는 방식이다. 링크(유일한 경로)를 미리 예약해 두는 것이기 때문에 만약 1Mbps의 대역폭인 링크를 사용하게 되면 100kbps인 사용자 10명 까지만 사용 가능한 것이다.
이 방식은 컴퓨터 네트워크에서는 비효율적이기 때문에 사용되지 않는다. 왜냐하면 사람들은 인터넷을 이용할 때 끊임없이 네트워크 통신을 하지 않는다. 예를 들어 스포츠 기사를 본다면 해당 기사를 클릭하고 읽는 동안의 몇분 간은 보통은 통신을 하지 않기 때문에 미리 예약해 둔 링크는 자원 낭비로 이어진다. 반면 전화는 연결 된 후부터 끊기 전 까지 계속해서 통신을 하는 것이기 때문에 이 경우에 적합한 방식이다.
packet switching (share)
현재 보통 사용하는 방식, 여러 호스트가 링크를 공유하여 사용한다.
송신 측에서 데이터를 일정한 크기의 패킷으로 나누어 전송하고 수신 측에서 이를 원래대로 재조립하여 읽는 방식
circuit switching과는 달리 상황에 따라 더 적합한 경로로 패킷을 전송한다.
Packet Switching의 4가지 지연 요소
nodal processing (processing delay)
에러가 발생한 적이 있는 패킷인지, 어떤 경로로 보내는 것이 적합할 지 등의 계산을 거치기 때문에 발생하는 delay.
queueing delay (90% 이상의 경우, 가장 가변적이어서 예측 불가)
패킷의 개수가 output link의 capacity를 넘어서게 되면 output link로 내보내지 않고 router의 buffer에 쌓이게 된다. 이 경우 packet들은 들어온 순서대로 자신의 차례를 기다리게 되고 이 때문에 delay가 발생하게 된다.
transmission delay
패킷이 output link로 나갈 때, 패킷의 맨 첫 부분이 나가기 시작한 시간 부터 맨 마지막 부분이 나가기 까지의 시간을 말한다.
propagation delay
패킷은 빛의 속도로 link를 통해 전송된다. 그렇기 때문에 다음 목적지 까지의 거리에 비례하여 delay가 길어진다. (물리적 거리)
Client-Server Architecture
Server
always-on host (항상 작동해야 한다)
permanent ip address (client가 해당 서버에 접속하려면 ip주소를 통해 접속이 가능한데, 이것이 계속 바뀌면 찾아서 접근할 수 없기 때문이다.)
Client
서버와 통신
간헐적으로 통신 가능 (필요로 할 때만)
IP주소 변경 해도 상관 없음
client끼리 서로 직접적으로 통신하지 않음 (서버를 통해)
Process Communication
동일 호스트의 경우
IPC를 사용하여 통신
다른 호스트의 경우
Message 교환을 통해 통신
Client Process => 능동적 (initiates communication)
Server Process => 수동적 (waites for contacts)
Socket
일반적으로 데이터 통신을 위한 창구(문), 우체통의 투입구 정도로 생각할 수 있다.
서로 다른 host의 process끼리 통신을 위해 서로의 socket을 연결한다.
application과 transport layer 사이의 interface이다.
SOCK_STREAM (TCP)
SOCK_DGRAM (UDP)
TCP 통신에서의 SOCKET PROGRAMMING 과정은 PPT 3장 참조
HTTP
TCP를 사용하기 때문에 클라이언트는 웹 서버의 80번 port와 연결한다. (80번인 이유는 위의 permanent ip와 같은 이유로 웹서버마다 서로 다른 port 번호를 사용하게 되면 클라이언트가 접근하기 힘들 수 있기 때문에 통일 한 것이다.)
http는 stateless하다. 이것은 https request, response를 통해 주고받은 데이터들은 어딘가에 저장되는 것이 아니라 통신할 때마다 잊게 되는 것을 의미한다.
non-persistent http는 tcp 연결을 유지하지 않고 통신을 할 때마다 매번 tcp 연결, 종료를 하여 새로운 연결을 맺는 것이고, persistent http는 그 반대로 tcp connection을 계속 유지하여 연결, 종료 과정을 다시 할 필요가 없는 것이다. (http 1버전은 non-persistent, 1.1 이상 버전은 connection: keep-alive 지원)
RTT (round trip time / 왕복 시간)
Multiplexing & Demultiplexing
의미
Multiplexing: sender측에서 여러 socket들로 부터 내려온 data들을 모아서 캡슐화하여 network layer로 내려보내는 것
Demultiplexing: receiver측에서 받아온 data를 각각 알맞는 소켓으로 올려보내는 것
UDP (connectionless)
dest port, dest ip addr 두가지만을 통해 어떤 소켓으로 demultiplexing 될 지 정해진다. (이 두개만 같다면 같은 socket으로 demux된다)
TCP (connection-oriented)
src port/ip, dest port/ip 의 네 가지가 동일한 경우에만 같은 socket으로 demux 된다.
UDP
특징
효율적이다. (에러 발생 여부, 신뢰 보장을 위한 작업 등이 없기 때문에 이에 소모되는 시간과 리소스가 절약된다.)
error & loss 대처가 거의 불가능하다. (header에 checksum은 존재하긴 한다)
패킷의 도착 순서가 보장되지 않는다.
신뢰가 보장되지 않음에도 사용되는 이유는 실시간 스트리밍 등의 서비스는 완전 무결한 데이터를 수신받는 것 보다도 속도가 더 중요하기 때문에 이런 곳에 쓰인다.
DNS에서 UDP를 사용한다. (tcp의 3-way / 4-way handshake 등을 하지 않아도 되기 때문에 시간이 크게 절약된다. 그리고 연결을 지속할 필요 없이 단 한번의 통신으로 용무가 끝나기 때문에 더 그렇다)
Reliable Data Transfer (RDT) (transport layer)
packet error 4 machanisms => error detection, feedback, retransmission, seq#
packet loss 1 machanism => timer
RDT 1.0
아래 레이어들에서 error/loss가 발생하지 않는 reliable한 상태가 보장되는 경우 => 해야하는일? 전혀 없음 (비현실적)
RDT 2.0
아래 레이어들에서 loss는 발생하지 않고 error만 발생하는 경우? => transport layer에서 packet error만 대비하면 된다.
error detection: packet의 header에 checksum bit를 넣어서 error가 발생한 적이 있는지 없는지 판단 가능하도록 한다.
feedback (Acks & Naks): receiver가 sender에게 에러 없는경우 ack, 있는 경우 nak을 전송하여 feedback을 준다.
retransmission: sender는 nak을 받게 된 packet을 재전송한다.
RDT 2.1 (sender에 seq# 추가, receiver에 discard 기능 추가)
만약, receiver측의 ack 또는 nak에 error가 발생한 경우? => sender는 ack 또는 nak를 받지 못한 packet을 재전송하게 된다. 하지만 이미 receiver는 이 packet을 받았다. 따라서 duplication이 발생한다. 이런 경우에 어떻게 처리할 수 있을까?
Handling Duplicate Packets
sender는 모든 패킷에 sequence number를 추가하여 중복 여부를 판단할 수 있다.
seq number에 1bit만을 사용하여 0,1을 번갈아가며 사용한다면? => 만약 0을 받고 ack 0을 보내고 1을 기다리고 있는데 ack가 error가 발생하여 sender측에서 0번을 다시 보냈다면 receiver는 이를 discard할 수 있게 된다. 그리고 discard하면서도 ack0을 보내서 0을 확실히 받았다는 것을 sender에게 feedback해준다.
RDT 2.2 (NAK-FREE)
2.1버전에서 nak를 제거한 것이다. nak를 제거해도 error 대처가 가능한 이유? => feedback으로 ack만을 보내는데, ack의 번호에는 가장 마지막으로 제대로 받은 packet의 seq#를 적어 보내게 된다. 그렇기 때문에 sender는 동일한 seq#인 ack를 중복하여 받게 된 경우에는 에러가 발생하였다는 것을 알 수 있다.
EX) 1~100번 패킷을 차례대로 전송하는 데 ack10이 연속하여 들어왔다면 최소한 11번은 제대로 도착하지 않았다는 것을 의미한다.
RDT 3.0 (error & loss)
아래 레이어들에서 loss까지 발생하는 경우에 대비할 수 있다.
loss detect => timer로 가능
sender는 reasonable한 시간동안 ack를 기다리고 그 시간 동안 도착하지 않는다면 loss라고 판단하게 된다.
loss가 아니어도 단순 지연으로 time out이 될 수도 있다. 이런 경우에는 2.1버전과 같이 재전송 후 discard한다.
Pipe Lined Protocols
실제 통신은 지금까지의 예시처럼 하나의 패킷을 전송하고 하나의 ack를 받고 다음 패킷을 전송하는 방식이 아니라 한번에 수많은 패킷을 쏟아 붓고 그에 따른 ack들을 받는 방식이다. 이것을 pipeline 방식이라고 한다.
그렇기 때문에 seq#는 1bit만이 아닌 더 많은 bit가 필요하고, sender와 receiver가 buffering을 해야한다.
pipelined protocol에는 go-back-N 방식과 selective repeat 방식의 두가지가 존재한다.
Go-Back-N 방식
window라는 것이 존재하고, sender는 window size만큼의 패킷을 한번에 전송한다.receiver는 하나의 패킷을 받을 때 마다 ack를 보낸다.
만약 error 또는 loss가 발생한 경우 예시) 1~10까지의 패킷을 전송해야 하고 window size가 4일 때, 맨 처음 1,2,3,4를 보낸다. 만약 1,2번 패킷은 정상적으로 받게 되었고 3번 패킷이 error or loss가 발생하였다면, sender는 ack1과 2를 받고 나서 5,6번 packet까지 전송하게 되어 receiver는 3을 받기 전에 4,5,6을 먼저 받게 된다. 하지만 4,5,6번 packet은 discard 시키며 ack 2를 보내어 3번 패킷이 정상적으로 도착하지 못했다는 것을 sender에게 알린다. sender는 이를 통해 3,4,5,6번 packet을 packet3 timeout 이후에 다시 보내게 된다.
Selective Repeat
GBN과 같이 window를 사용하지만, 이전의 패킷이 loss되었더라도 receiver의 window에 패킷들을 저장해둔다. 그렇기 때문에 GBN에서 정상적으로 도착한 패킷들도 전부 버렸던 비효율적인 부분이 없다.
예시) 1~10까지의 패킷을 전송해야 하고, window size가 4일 때, 맨 처음 sender는 1,2,3,4번 패킷을 보낸다. 그런데 만약 3번 패킷이 loss가 발생했다면? => sender는 ack1,2를 받았기 때문에 5,6번 packet까지 전송하게 된다. 하지만 3번 packet은 도착하지 않았기 때문에 reciver의 window에서 3번의 자리를 비워두고나서 정상적으로 도착한 4,5,6번 패킷을 넣는다. 그리고 ack4,5,6 또한 전송한다. 이렇게 되면 sender는 ack3을 받지 못했기 때문에 timer에 의해 time out이 발생하게 되고 3번 packet을 재전송하게 된다. 이것이 정상적으로 전송되었다면 receiver의 window의 빈자리였던 3번이 채워지게 되면서 3,4,5,6번 패킷을 한번에 상위 레이어로 올려보내게 된다. (delivered) 그리고 receiver는 ack3을 보내어 그 뒤로 7번 패킷부터 받게 된다.
Selective Repeat의 딜레마
만약 window size가 3이고 seq#에 2bit만을 사용하여 0,1,2,3이 번갈아가며 사용되는 경우에 0,1,2번 패킷이 정상적으로 도착했지만 ack0,1,2가 모두 loss되었다면? sender에 timeout이 발생하여 sender는 0번 패킷부터 다시 재전송하게 된다. 하지만 receiver입장에서는 이미 window가 [3,0,1,2]에 가있는데 여기서 0번이 오게 되면 앞에서 누락된 0번이 아닌 한바퀴 돈 후의 0번 패킷인 줄 알고 window에 넣게 된다. 이런 문제가 발생하지 않으려면 어떻게 해야할까?
=> seq#를 최소한 window size의 두배 이상으로 만든다.
TCP
TCP segment structure (생략)
https://ingyeoking13.tistory.com/273
reliable data transfer
cumulative acks (ack n = n번 까지 잘 받았다. 만약 1~10전송 3loss면 ack2 까지만 보내진다.)
pipelined segments (window size만큼 한번에 전송)
single retransmission timer (단 한개의 timer만이 존재, oldest unacked segment를 위한 것, timeout 발생하면 해당 segment 재전송 후 timer 재시작, unacked였던 segment의 ack가 도착하면 timer 재시작)
seq#는 segment의 데이터의 첫 번째 byte의 byte-stream number (전체 중 몇 번째인지)이다.
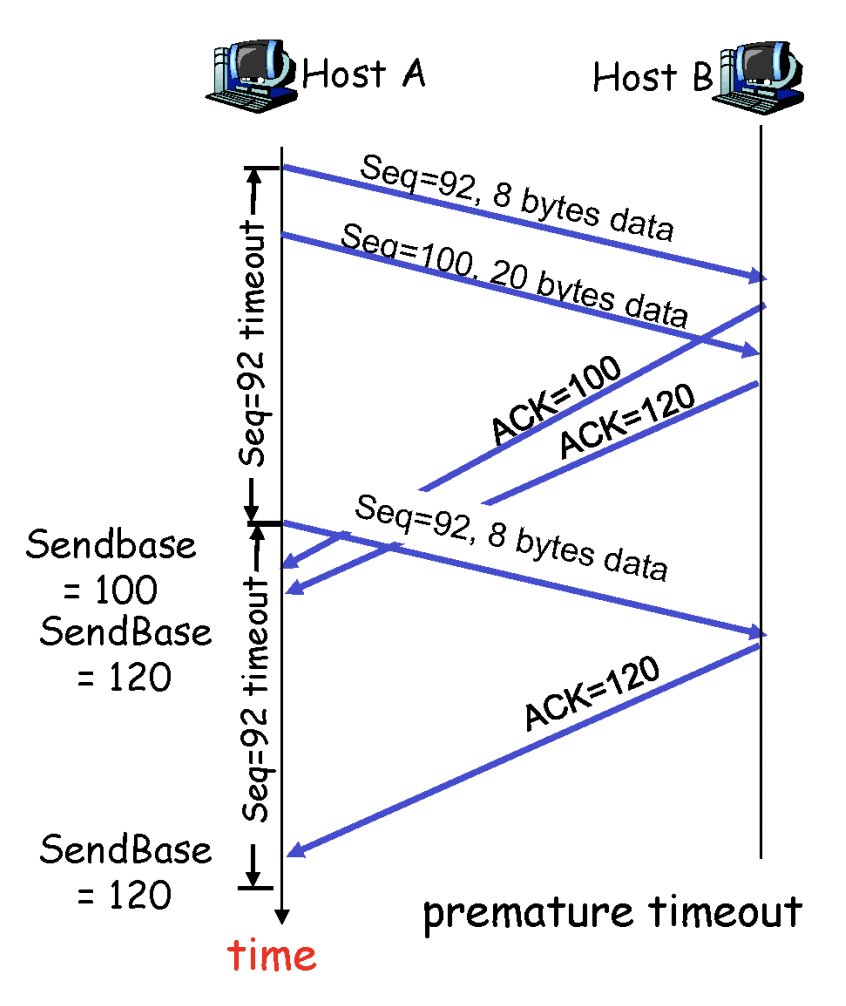
위의 사진은 rtt보다 timer 제한이 더 작아서 발생한 문제이다. receiver는 seq #119까지 이미 잘 받았지만, sender에서 timeout이 발생하여 92번부터 8바이트 만큼의 segment를 재전송하였다. 이 경우, 방금 받은 것은 92~99번 바이트의 데이터이지만 이미 receiver는 #119까지 받은 상태이므로 ack 120을 보내게 된다. (tcp rdt에서 ack n = n-1까지 잘 받았고 n번 보내라는 의미)
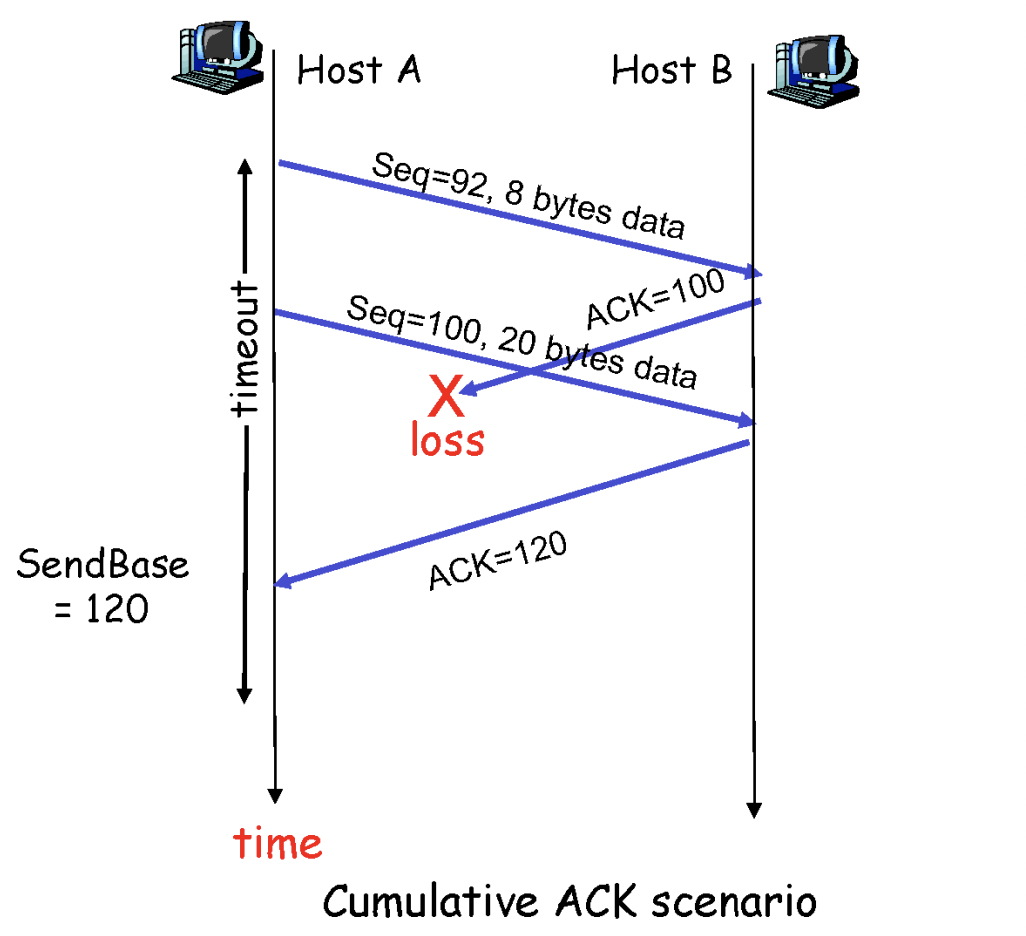
위의 사진의 경우는 92~99, 100~119의 데이터를 받고, ack100이 loss된 상황이다. 하지만 sender는 ack120을 받았기 때문에 ack100을 못받은 것에 대해 아무런 문제가 없다. (cumulative 때문)
Flow Control (흐름 제어)
TCP connection의 receiver에는 buffer가 있다. 그런데 만약 전송 속도가 reciever측의 application layer의 process의 처리 속도보다 빠르다면? buffer overflow가 발생하게 되어 loss가 발생한다 (capacity 초과되면 segment를 버린다)
GBN으로 구현할 수 있다. receiver측의 buffer에 window size만큼의 spare 공간을 확보해두어 sender의 확인/응답 과정이 필요없는 한번의 전송량을 window size만큼으로 제한한다면 overflow가 발생하지 않는다. 만약 loss가 발생하여도 어차피 discard하기 때문에 window size는 초과될 수 없다. 이는 호스트들이 tcp 3-way handshake 과정에서 receiver의 window size만큼으로 sender의 window size를 제한하기 때문에 가능하다.
selective repeat으로도 구현 가능
하나의 segment를 전송하고 ack를 받아야만 다음 것을 전송하는 방식인 stop-and-wait를 사용할 수도 있지만 비효율적이다.
connection management
connection establish를 위한 TCP 3-way handshake와 connection close를 위한 TCP 4-way handshake에 대한 내용인데 이는 pdf 7장 참고
3-way handshake에서 마지막 sender -> receiver ack에는 data를 첨부할 수 있다.
congestion control (혼잡 제어)
congestion control은 호스트들 간이 아닌 호스트 사이의 네트워크에 부담을 주지 않기 위한 것이다.
다수가 공용으로 사용하는 네트워크이기 때문에 모두가 네트워크에 overflow가 발생하지 않도록 하기 위해 지키는 규칙이다. 다같이 전송량을 늘리다가 한계를 느끼면 모두가 발을 빼서 다시 낮은 전송량부터 시작하는 것이다.
3가지 phase가 있다. (slow start, additive increase, multiplicative decrease)
처음에는 네트워크의 혼잡도에 대해 알지 못한다. 그렇기 때문에 0부터 시작하여 빠른 속도로 전송 속도를 늘린다. (빠른 속도 = exponential 2의 지수) (connection 시작 시 congestion window size = 1MSS)
threshold에 도달했다면, additive increase로 전환하여 느린 속도로 속도를 늘린다. (loss가 발견되기 전 까지 매 RTT마다 congestion window size를 1MSS만큼 늘린다. => linear grow // MSS = maximum segment size)
만약 triple duplicate ack가 발생했다면 threshold = congestion window size/2 & congestion window size = threshold가 된다. 중복되는 ack가 3번 연속 도착했다는 것은 timeout이 아니어도 loss가 발생한 것을 확신할 수 있기 때문이다.
만약 loss가 발생했다면 이는 buffer overflow에 의해 loss된 것이기 때문에 다시 slow start로 돌아간다. (threshold = congestion window size / 2,congestion window size = 1MSS)
과연 위의 congestion control 방식을 따르면 모든 호스트들은 네트워크를 공평하게 사용하게 될까?
그렇다. 위의 과정을 계속 반복하게 되면 결국 모두 공평한 속도로 수렴하게 된다 (pdf 8장 그림 참조)
2. NETWORK LAYER
Forwarding
패킷을 라우터에서 다음 라우터로 전송하는 것
라우팅
src에서 dest로 이동하기 위한 경로를 정하는 것
IP Datagram Format
생략 pdf 10장 참고
Scalability
같은 prefix인 host들을 한 곳에 모아놓아 경로를 찾기 쉽게 한다. 새로운 host를 추가하기에도 용이하다.
Network Class
A~E까지 존재하며 Class A는 network ID가 8bit, host ID가 24bit여서 총 2의 24승 만큼의 host를 가질 수 있고, Class B는 16/16, Class C는 24/8이다. 하지만 이는 매우 큰 비효율을 만들기 때문에 지금은 사용하지 않는다. (Class A에 소속된 network는 정말 1600만명 가량의 host ID를 모두 사용하는가? Class C는 256명의 host ID만으로 충분한가? 그렇지 않다)
Classless Inter Domain Routing (No Class)
만약 15bit만큼만 network ID로 사용하고 싶다면, IP주소/15로 표기하고 subnet mask를 11111111.11111110.00000000.000000000 (255.254.0.0)으로 하여 network ID가 무엇인지 알 수 있다.
CIDR Makes Packet Forwarding Harder
만약 201.10.0.0/21 서브넷과 201.10.6.0/23 서브넷이 있다고 할 때, 201.10.6.17은 어느 서브넷의 호스트인가? => Longest Prefix Match로 결정된다.
이 경우 201.10.6.0/23의 prefix와 더 많은 부분이 겹치게 되므로 이 서브넷의 host임을 알 수 있게 된다.
Subnet
같은 prefix를 가지는 host들의 집합이다.
같은 서브넷에 속한 host들 끼리는 router를 거치지 않고 통신이 가능하다.
NAT (Network Address Translation)
IPv4 protocol은 약 42억 6천만개의 IP를 만들 수 있다. 하지만 요즘은 한명 당 여러개의 디바이스를 인터넷에 연결하는 등의 이유로 IP주소의 개수가 부족해졌다. 하지만 우리는 여전히 IPv4 프로토콜을 사용하고 있다. 그것은 NAT가 있기 때문이다.
마치 single IP addr로 보이는 IP를 NAT에 연결된 host들에게 제공한다. 이 IP주소들은 그 내부에서는 고유한 IP이지만 전체 네트워크에서는 그렇지 않다.
위의 이유로, NAT router를 거쳐 외부의 라우터로 전송될 때는, host의 내부 ip주소가 아닌, 바깥에서 사용할 ip address가 src ip address로 적혀 나가게 된다. 이 때, NAT 내부의 모든 사용자들의 ip가 동일해지기 때문에 response를 받을 때에는 port number로 이들을 구분하게 된다.
short term remedy이다. IP부족 문제를 해결하기 위한 임시방편 땜빵정도로 생각
DHCP (Dynamic Host Configuration Protocol / Plug and Play)
만약 사용자가 카페에 가서 자신의 노트북을 와이파이에 연결한다고 할 때, 연결이 되어도 노트북은 자신의 IP주소가 무엇인지 알 수 없다. 이를 알기 위한 프로토콜이 DHCP이다.
DHCP 과정은 총 4가지로 나뉜다.
1. DHCP discover
src ip: 0.0.0.0:68 (unknown)
dest ip: 255.255.255.255:67 (broadcast, because unknown)
yiaddr: 0.0.0.0 (unknown, not received)
transaction ID: 654
아직 자신의 ip주소를 할당받지 못했기 때문에 source ip addr를 0.0.0.0 두었고, DHCP 서버의 주소 또한 모르기 때문에 모든 host가 이 메세지를 받을 수 있도록 broadcast로 전송한다. yiaddr는 dhcp서버로부터 아직 받은 것이 없기 때문에 이렇게 작성한다.
2. DHCP offer
src ip: 223.1.2.5:67
dest ip: 255.255.255.255:68
yiaddr: 223.1.2.4
transaction ID: 654
lifetime: 3600secs
DHCP 서버로부터 ip addr를 제시 받은 상황이다. DHCP서버는 같은 서브넷 내에 여러개가 존재할 수 있고 그렇기 때문에 offer 또한 여러개를 받을 수 있다.
dest ip가 broadcast인 이유는, 아직 host는 자신의 ip주소를 확정하지 않았기 때문이다.
3. DHCP request
src ip: 0.0.0.0:68
dest ip: 255.255.255.255:67
yiaddr: 223.1.2.4
transaction ID: 655
lifetime: 3600secs
host가 yiaddr의 ip address를 사용하고 싶다고 DHCP서버에 요청한 상황이다. 여기서 DHCP offer에서 DHCP서버의 ip주소를 알아냈음에도 broadcast로 전송한 이유는 앞서 말했듯이 DHCP서버는 여러개가 존재할 수 있고 그 DHCP서버들이 제시한 여러개의 IP address중에 한가지만을 정해서 request를 보내는 것이기 때문에 broadcast로 전송하여 해당 yiaddr를 제시한 DHCP서버만이 이 request를 받아들일 수 있도록 하는 것이다.
src ip addr가 아직 0.0.0.0인 이유는 아직 host 자신의 ip주소는 확정된 것이 아니기 때문이다.
4. DHCP ACK
src ip: 223.1.2.5:67
dest ip: 255.255.255.255:68
yiaddr: 223.1.2.4
transaction ID: 655
lifetime: 3600secs
이 과정을 통해 host는 자신의 IP주소를 확실하게 할당 받아 사용 가능해지게 된다. 여기서도 dest ip addr가 broadcast인 이유는 역시 host가 이 ack를 받기 전까지는 자신의 ip주소를 확정하지 못한 상태이기 때문에 yiaddr로 보내면 받지 못하기 때문이다.
IP Fragmentation & Reassemble (MTU)
MTU는 Maximum Transfer Size를 뜻한다. 이는 Link마다 다르며, 만약 여러 link를 통해 데이터가 전송될 때, 중간에 위치한 link의 MTU가 매우 작은 경우가 있을 수 있다. 이런 경우에 IP Datagram이 MTU에 맞게 여러 조각 (Fragment)로 쪼개지며, 이렇게 쪼개진 조각들은 반드시 최종 목적지에서만 reassemble된다.
reassemble시에 순서를 맞추기 위하여 IP datagram의 header에 위치한 flags, fragment offset bit에 순서 정보가 기록된다.
예를 들어, 4000바이트 크기의 IP datagram이 MTU가 1500byte인 link를 통해 전송되어야 한다면 IP datagram의 header의 크기가 20bytes이기 때문에 datafield의 크기가 1480, 1480, 1040인 3개의 datagram fragment로 나뉘어 전송된다.
ICMP (Internet Control Message Protocol)
여러 정보를 컨트롤하거나 전달하기 위해 사용하는 프로토콜 (error 알림 => 만약 전달해야할 host가 꺼져있다면? 물리적인 link가 절단된 상태라면? 이런 예외 상황에 어떤 부분에서 error가 발생했는지 알려주어 힌트가 되기도 한다, ping/tracerouter 등의 명령에 사용)
Transition from IPv4 to IPv6
tunneling을 사용한다. IPv4 router는 IPv6를 이해할 수 없지만, 반대는 가능하다. 그렇기 때문에 만약 IPv6가 IPv4와 동시에 사용된다면 IPv6 router측에서 IPv4를 읽고 다음 라우터가 어떤 라우터인지에 따라 어떤 데이터를 전송할지 결정해야한다.
IPv4 -> IPv6 : IPv6 router에서 IPv4 헤더를 이해한다.
IPv6 -> IPv4 : IPv6 router에서 다음 router가 이해할 수 있도록 IPv4 header로 변환하여 전달한다.
Routing Algorithms
Static Routing Algorithm => 사람이 직접 link cost를 수정한다. 느리고 인력이 많이 필요하다.
Dynamic Routing Algorithm => 라우터가 주기적으로 직접 수정한다.
네트워크의 연결 상태는 그래프와 같이 볼 수 있다. (nodes & edges)
Routing Algorithm에는 두가지가 있다. (Link State, Distance Vector)
Link State는 전체 네트워크의 그래프를 모두 보고 최적의 경로를 찾아 forwarding table을 작성하는 방법이다 (global). 매우 직관적이라는 장점이 있지만 네트워크의 크기가 커질 수록 비현실적인 방법이 된다. 이는 곧 다익스트라 알고리즘과 같다. (이미 알기 때문에 필기 생략, 말로 설명은 가능하도록)
Distance Vector는 가장 먼저 자신의 이웃 node들까지의 최단경로를 작성하고, 이 정보를 자신의 모든 이웃 node들에게 전달한다 (decentralize). 그리고 다른 node의 최단경로 정보를 전달 받은 node들은 전달 받을 때 마다 자신의 forwarding table을 갱신한다. 만약 갱신 이전과 이후의 결과가 같다면 이웃들에게 전달하지 않는다.
벨만포드 알고리즘과 같다.
Distance Vector 방식의 문제점 => link cost change
list cost change의 두 가지 경우 => cost 증가, cost 감소
Cost 감소의 경우, 문제가 없다.
Cost 증가의 경우, 문제가 발생한다.
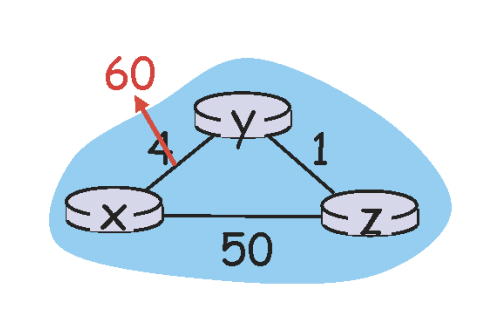
위의 그림과 같이 link cost가 증가된 경우를 생각해본다.
변경 되기 전의 forwarding table은 y->x의 cost가 4였을 것이다.
그리고 이렇게 변경된 이후에는 이 값이 60으로 변경되고, z->x의 cost가 5(4+1)인 것을 알기 때문에 (y->z) + (z->x) = 1+5 = 6으로 계산할 것이다.
하지만 사실 z->x가 5였던 이유는 자기자신(y)를 거쳐갈 때 5였던 것이고 y->x의 경로가 60으로 증가한 이후에는 z->x가 5가 아닌데 y는 이것을 모른다. 그냥 z까지만 가면 z에서 x로 5만에 갈 수 있는 어떤 경로가 있을 것이라고 판단하게 된다.
그래서 이러한 오류가 발생해 y->x가 6으로 갱신되면 z는 z->x까지의 거리가 7일 것이라고 판단하여 7로 갱신되고, 그렇다면 다시 y->x는 8로 갱신되고 이러한 불필요한 과정이 y->x가 51이 될 때 까지 반복된다. (count to infinity, poisoned reverse)
그래서 이를 해결하기 위해, 만약 z->x의 최단 경로가 y를 거쳐가는 경로라면, z는 y에게 자신의 갱신된 정보를 알려줄 때 이 정보를 무한대로 보내주게 된다. 이렇게 하면 위와 같은 문제를 피할 수 있다.
Hierarchical Routing
네트워크에 수많은 서브넷이 존재한다. 그리고 각각의 서브넷들은 LS, DV중 한가지의 Routing Algorithm을 사용한다 (Autonomous Systems / AS / Intra-AS). 그렇다면 이들 사이의 Routing Algorithm은 어떻게 사용될 수 있을까? 강의 다시듣기
Customers & Providers
Customer = 을 / Provider = 갑
현실에서 provider는 이동통신사, customer은 개인 고객이다.
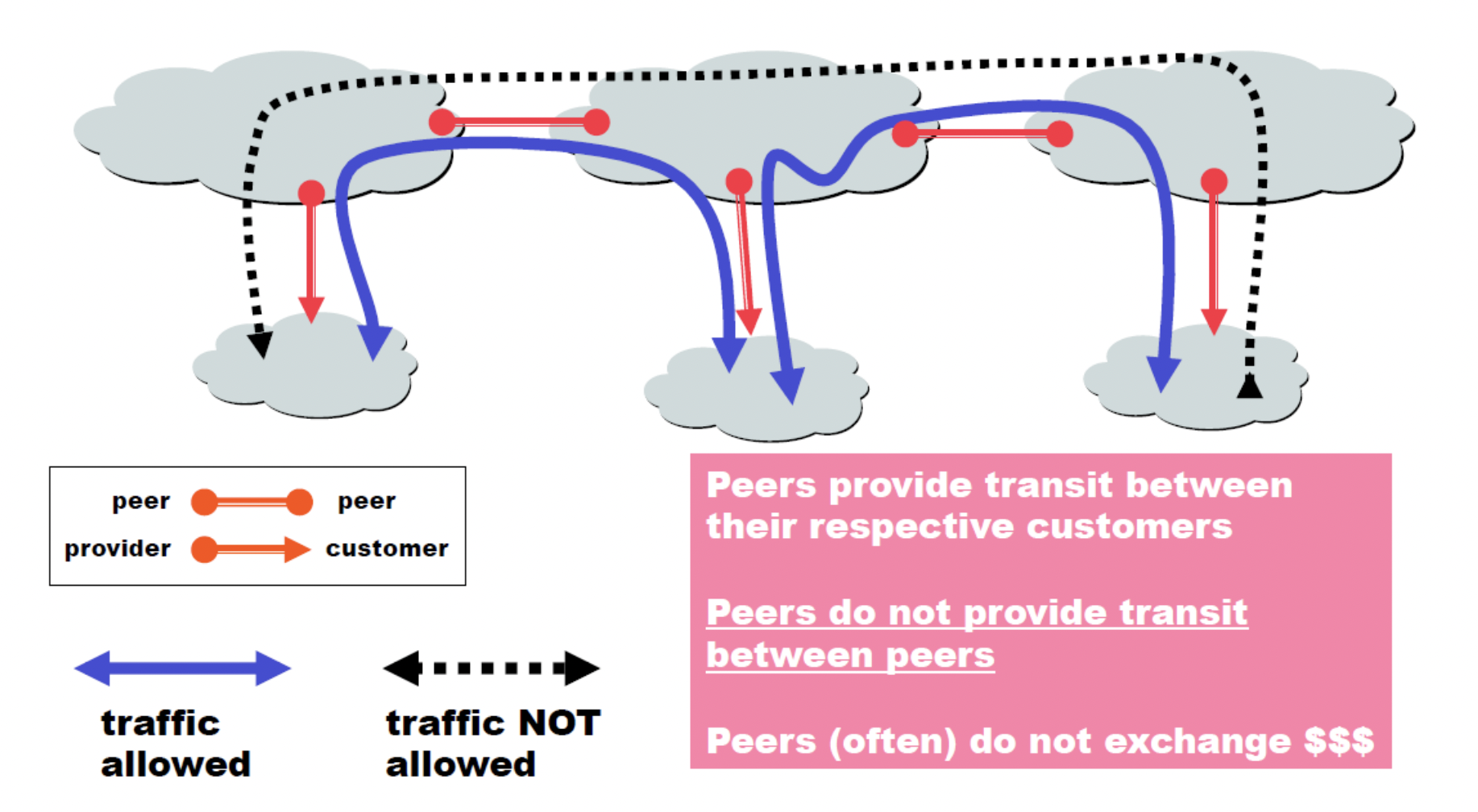
위의 사진에서 위쪽의 큰 구름 세개가 provider(peer), 작은 구름 세개가 customer라고 할 수 있는데, 왼쪽 peer/customer부터 차례대로 A,B,C라고 한다면 customer A에서 customer B로 트래픽을 보낼 수 있다. 하지만 A에서 C는 불가능하다. 그 이유는 A와C사이의 B는 자신의 고객에게 아무것도 내려주지 않고 그저 A와 C를 이어주는 역할만 하는 것이기 때문에 얻는 것 없이 A로부터 받은 것을 C로 무상으로 넘겨주는 것이고 이는 B입장에서 손실이다 (돈 못받음)
BGP (Border Gateway Protocol)
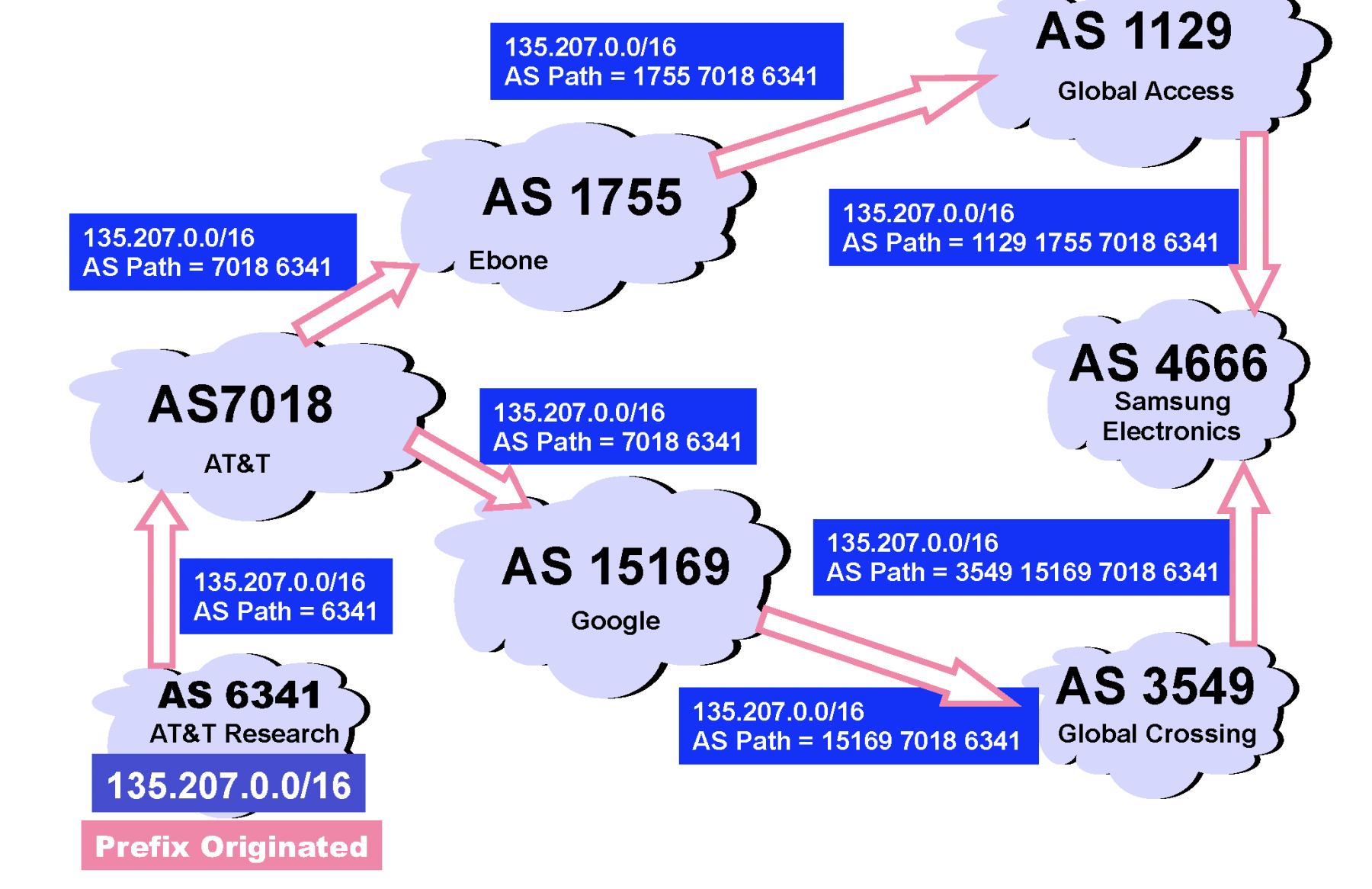
위의 그림과 같은 경우에, AS6341에서 AS4666으로 가는 최소 hop 경로는 두가지이다. 그렇다면 이 두가지 경우 중에 어떤 것을 선택할까? 이는 기술적인 이유보다는 경제적, 정치적 문제로 결정된다. 만약 우리나라에서 유럽으로 데이터를 전송한다고 할 때, 북한을 거쳐가는 경로가 최적의 경로라고 하더라도 우리는 북한에 우리의 정보가 거쳐가는 것을 정치적 이유로 원하지 않는다. 그래서 다른 경로를 선택하게 된다.
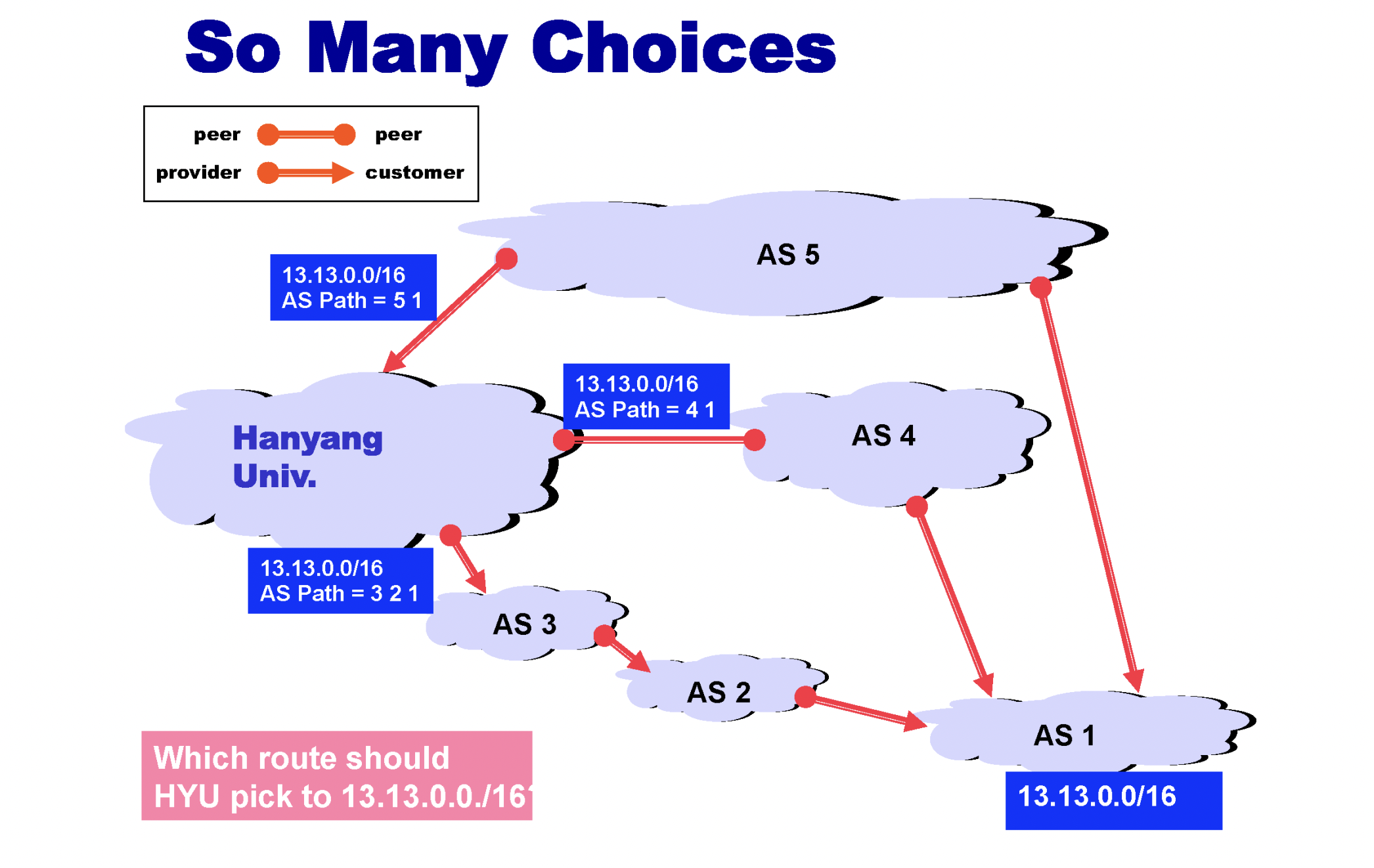
위와 같은 경우도 있다. 한양대학교에서 출발하여 AS1까지 가는 최단 경로는 AS5나 AS4이지만 현실적으로는 AS3, AS2를 거쳐가는 경로를 선택하게 된다. 그 이유는 provider가 자신의 고객 AS만을 거쳐가도록 하는 것이 경제적으로 좋기 때문이다. (돈벌려고)
3. LINK LAYER
Multiple Access
Broadcast (shared medium)방식으로 link가 연결되어 있을 때, 하나의 host가 link를 통해 데이터를 전송 중일 때 다른 host도 데이터를 전송하게 된다면, 이는 전기 신호이기 때문에 서로 섞여 noise가 되어 무슨 신호인지 알 수 없게 된다.
그렇기 떄문에 이런 충돌 (collision)을 막기 위해 여러가지 protocol들이 존재한다. 이들은 MAC protocol이라고 불리며 MAC은 Multiple Access Control의 약자이다. (channel partitioning, random access, taking turns 3가지에 대해 배운다)
channel partitioning
채널을 작은 조각으로 나눈다. 그리고 그 조각들은 각각의 node가 exclusive하게 사용한다.
TDMA (Time Division Multiple Access)가 있다.
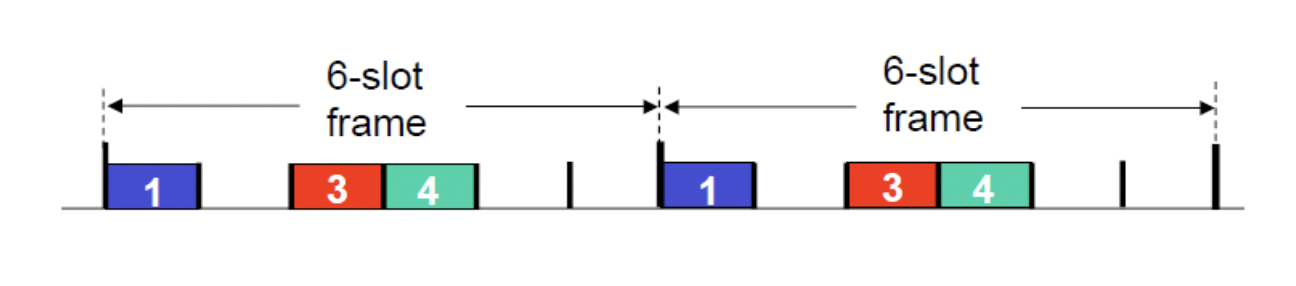
위의 사진과 같은 방식으로 사용되는데, 보다시피 6개의 slot을 각각 round마다 exclusive하게 사용하도록 하였지만 정작 2,5,6은 이를 계속 사용하지 않아 자원 낭비가 발생한다. 이런 단점이 있을 수 있다.
FDMA (Frequency Division Multiple Access)도 있다. TDMA는 slot으로 나누어 round마다 돌아가며 사용하도록 하였지만 FDMA는 slot대신 각각의 주파수를 다르게 하여 multiple access가 가능하도록 한 것이다. 하지만 이 역시도 주파수를 배정해주었음에도 장시간 사용하지 않는 host들이 있는 경우 자원 낭비가 될 수 있다.
Random Access
전송해야할 데이터가 있다면 그냥 제때 제때 전송하도록 하는 방식이다. 매우 일반적이고 효율적이지만 collision의 위험이 있기 때문에 별도의 조치가 필요한 방식이다. 이 방식을 사용하려면 collision이 발생하였을 경우에 대처가 필요하고, collision을 감지하였다면 즉시 전송을 그만두어 불필요한 자원 낭비가 길게 발생하지 않도록 해야한다.
현재 가장 일반적인 프로토콜은 random access의 CSMA/CD (Ethernet), CSMA/CA (wireless)이다.
CSMA는 Carrier Sense Multiple Access의 약자이다. 즉 충돌을 방지하기 전에 미리 sense (listen)한다는 것이다. 자신이 말하기 전에 미리 한번 들어보고, 만약 누군가의 소리가 들린다면 말을 하지 않아야된다는 것을 알 수 있다는 원리이다.
하지만 이는 절대적으로 충돌을 막을 수 있지 않다. 왜냐하면 말하기 전에 들어보았는데 조용하였고, 그래서 말하기 시작했는데 나와 같은 생각을 하여 동시에 말하기 시작한 다른 사람이 있을 수 있고 이는 충돌로 이어지기 때문이다. 사실 동시라는 것은 말이 되지않는다. 분명 누군가는 조금이라도 먼저 말했다. 하지만 propagation delay라는 매우 현실적인 문제 때문에 그 조금의 차이동안 sense할 수 없게 되는 것이다. propagation delay는 해결할 수 없는 문제이다. 따라서 다른 해결 방법을 생각해야만 한다. (binary exponential backoff)
해결 방법은 backoff이다. 충돌이 발생했다면 이를 감지한 후 전송을 즉시 중단하고, n=충돌감지횟수 라고 할 때 0~2^n까지의 시간 중 랜덤 시간 만큼 backoff를 하였다가 재전송을 한다. 즉 충돌 횟수가 많아질 수록 backoff 시간은 늘어난다. 이렇게 한 이유는 현재 충돌의 원인이 되는 host가 얼마나 많은지 알 수 없기 때문에 우선 작은 시간부터 기다려보고 계속해서 충돌이 발생하면 보다 오랜 시간을 기다려서 재전송을 하게 하는 것이다.
CD는 collision detection의 약자이며 충돌을 감지할 수 있기 때문에 충돌 발생 시 데이터 전송을 바로 중단하여 불필요한 시간/자원 낭비를 줄이도록 하는 것이다.
Taking Turns
위의 두 방식의 장점만을 뽑아서 만든 것이다.
polling 방식이 있는데, 이것은 하나의 master가 있고 그 밑에 여러개의 slave들이 있다.
master는 마치 토크쇼의 mc처럼 현재 말을 하고싶은 host들의 요청을 듣고 누가 먼저 말할 지 정해준다.
master가 멈추면 네트워크 전체가 멈추게 된다는 치명적 단점이 있다.
token passing 방식도 있는데, 이는 원모양으로 서로 토큰을 돌리며 발언권을 순서대로 얻는 방식이다. 하지만 token을 넘겨주는 과정에서 token이 유실된다면 큰 문제가 발생한다는 치명적인 단점이 있다.
Ehternet
유선 통신이다.
옛날에는 bus형태(broadcast, 충돌 발생)를 많이 사용했지만 현재는 중앙에 switch를 두고 그 switch에 host들이 연결되어있는 형태를 주로 사용한다. (star형태는 collision 발생하지 않는다.)
Ethernet Frame Structure => pdf 16장 참고

MAC Address
각각의 NIC (Network Interface Card)들이 고유하게 가지고 있는 주소 (length = 48bits)
Network Layer로 forwarding하기 위해 사용된다. (IP Packet의 dest는 최종 목적지의 IP주소가 적혀있지만 Frame의 destination address에는 다음 router의 MAC Address가 적혀있다. 이 MAC Address를 따라 이동하여 최종적으로 최종 목적지에 도달할 수 있는 것이다. Network Layer에서 dest IP addr 확인, 해당 router의 forwarding table lookup, 해당 router의 ARP table lookup하여 다음 router의 MAC Address 확인, header 작성 후 다음 router로 전송)
ARP protocol
A가 B에게 데이터를 전송하고 싶은데 A는 B의 MAC Addr를 모르고 있는 경우 어떻게 할까?
A는 B의 IP주소가 data에 담겨있는 ARP Request Query를 broadcast로 전송한다. (Frame Dest Addr = All 1, FF-FF-FF-FF-FF) MAC Address로 broadcast하는 것도 모든 bit 1이다.
모든 host가 이 쿼리를 받게 되고, 자신의 것이 아니면 무시한다. B는 IP packet에 자신의 IP주소가 담겨있는 것을 확인하고 이에대한 response로 자신의 MAC 주소를 header의 src MAC Address에 넣어 보내준다. (오직 한명만 response할 수 있으므로 이는 Unicast로 들어온다.)
A는 이 response를 받아 자신의 ARP Table에 기록한다. 이 기록은 timer가 있기 때문에 timeout 발생 전까지만 유지된다.
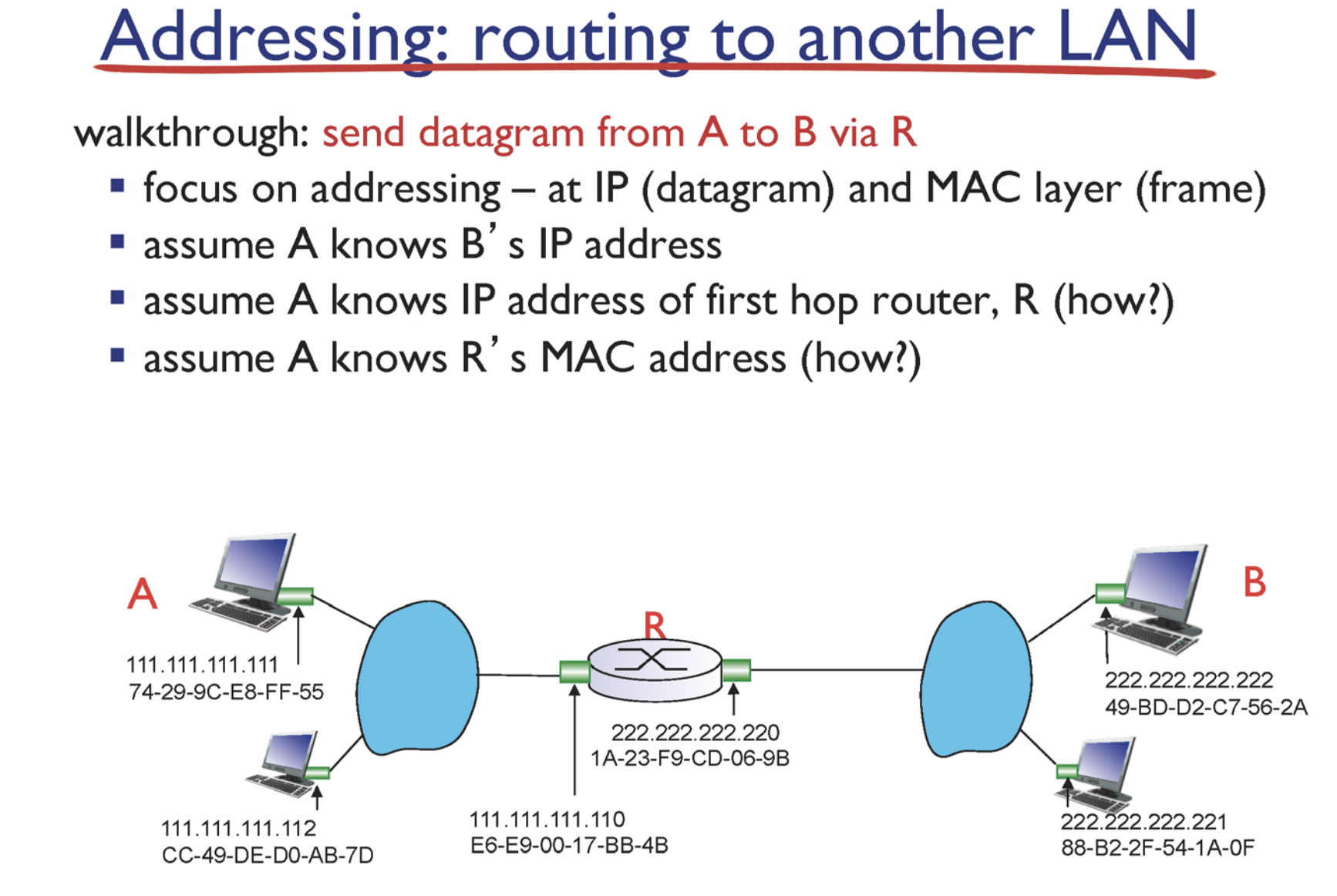
위와 같은 상황을 가정해본다.
A는 라우터R의 IP주소를 알고있다. 그 이유는 DHCP때문이다. A는 맨 처음 IP주소를 할당받기 위해 네트워크에 연결되었을 때 DHCP서버와 통신을 하게 되고, 이 때 DHCP서버로부터의 ack (ip packet)에 src address로 들어있었을 것이다.
A는 라우터R의 MAC주소 또한 알고있다. 그 이유는 A는 R의 IP Address를 알고있기 때문에 ARP request로 R의 MAC 주소를 알아낼 수 있다.
Switch
전이중화 통신 가능
collision 발생하지 않음 (star와 같은 형태로 중앙의 switch에 연결)
switch table이 존재해서, 특정 호스트에게 전달하려면 스위치의 몇번 포트로 전달 해야 하는 지 알 수 있다. (MAC Address : Port Number)
switch table은 self-learning 방식으로 기록된다.
self-learning 방식: switch는 자신이 전달 받은 frame의 src Mac address를 보고 이를 기록해두어 나중에 사용할 수 있도록 한다.
만약 기록되어있지 않은 MAC address에게 데이터를 전달해야한다면, 어떻게 할 수 있을까? => flooding을 사용한다. 데이터를 전달해준 port를 제외한 모든 port로 frame을 보내는 방식이다.
Security
HTTP통신은 데이터를 평문 상태로 보내기 때문에 중간에 데이터가 탈취된다면 데이터를 그대로 노출시키는 보안 문제로 이어질 수 있습니다.
대칭키
대칭키란 암호화 하는 키와 복호화하는 키가 같은 것을 말합니다. g(g(x)) = x
동일한 키를 주고 받기 때문에 매우 빠르다는 장점이 있지만, 클라이언트-서버 사이에 대칭키를 전달하는 과정에서 탈취될 위험이 있습니다.
비밀키, 공개키
대칭키의 위와 같은 문제점 때문에, 서버는 다른 사람이 알아도 되는 공개키를 공개하고, 그 공개키로 암호화된 데이터를 자신만이 가진 비밀키로 복호화합니다.
공개키 암호화 방식: 클라이언트가 A, 서버가 B라고 했을 때, A는 데이터를 B가 공개한 공개키로 암호화하여 B에게 전달합니다. 그리고 B는 자신만이 가진 비밀키로 데이터를 복호화하고, response를 할 때 공개키로 암호화하여 A에게 전달합니다. A는 이를 받아 자신의 비밀키로 데이터를 복호화합니다.
이 방식은 confidentiality (기밀)은 보장하지만, integrity(무결성)과 Authenticity(확실성)은 보장하지 않습니다.
하이브리드 방식 (대칭키 방식 + 공개키 방식)
위의 두 방식은 각자의 장점과 단점을 가지고 있습니다. 그렇기 때문에 각자의 장점을 잘 살리는 방향으로 합친 것입니다.
대칭키 방식은 대칭키를 전달하는 과정에서 탈취 위험이 단점이었습니다. 하지만 공개키 방식을 사용하여 대칭키로 사용할 키를 공개키로 암호화하여 전달한다면 탈취되어도 공격자는 이를 복호화 할 수 없습니다. 따라서 대칭키가 유출될 가능성이 적습니다.
위의 설명과 같이, 클라이언트 = A, 서버 = B 라고할 때, A는 대칭키로 사용하고자 하는 키를 B의 공개키로 암호화한 후에 B에게 전달합니다. B는 이를 받고 자신의 비밀키로 복호화하여 대칭키로 사용하고자 하는 키가 무엇인지 알게됩니다. 이렇게 되면 A와 B는 안전하게 대칭키를 주고받았습니다. 이제 이 대칭키를 사용하여 대칭키 방식으로 HTTP통신을 하게됩니다.
요약: 첫 통신 = 공개키 방식 / 그 이후 = 대칭키 방식
HTTPS
위에서 설명한 바와 같이, HTTP통신은 text를 평문으로 전달하는 과정이기 때문에 중간에 노출된다면 민감한 정보가 그대로 드러나는 문제가 발생할 수 있습니다. 이를 해결하기위해 기존의 HTTP방식을 SSL 프로토콜과 결합하여 보안을 강화시킨 것입니다.
항상 안전한 것 만은 아니다. 왜냐하면 신뢰도가 높은 CA가 발급한 인증서가 아닌 자체제작한 인증서 등을 사용하면 안전하다고 볼 수 없다.
HTTPS 통신 흐름
HTTPS통신을 희망하는 서버(A)는 공개키와 비밀키를 만든다.
믿을만한 CA (certificate authority)에게 자신의 공개키 관리를 맡긴다.
CA는 해당 기업의 이름, A의 공개키, 공개키 암호화 방식을 담은 인증서를 만들고 이를 자신들 (CA기업)의 개인키로 암호화하여 인증서를 A에게 넘겨줍니다.
A서버는 이제 인증서를 갖고있다. 만약 자신에게 자신의 공개키로 암호화되지 않은 요청이 오면, 이 인증서를 클라이언트에게 전달한다.
클라이언트는 이 인증서를 CA기업의 공개키로 복호화하여 A의 공개키를 알아내고 자신이 보내고자하는 데이터를 A의 공개키로 암호화하여 전달한다. 여기서 클라이언트가 CA의 공개키를 알고 있는 이유는 CA는 검증된 기업이기 때문에 브라우저가 인증서를 탐색하여 알아낼 수 있는 것이다.
A는 자신의 공개키로 암호화된 데이터를 받아 자신의 비밀키로 복호화하여 데이터를 읽을 수 있게 된다.
TLS/SSL Handshake
HTTPS에서 서버와 클라이언트 간의 통신 이전에 SSL 인증서로 신뢰성을 판단하기 위한 과정
TLS/SSL Handshake 과정
클라이언트가 서버에게 client hello 메세지를 보낸다. 이 메세지에는 버전(?), 암호 알고리즘, 압축 방법을 함께 담는다.
서버에서는 이를 받아서 CA 인증서, 세션 ID를 담은 server hello 메세지를 보낸다. 이 인증서에는 서버 A의 공개키가 담겨있고 이는 대칭키 생성/공유 전 handshake과정에서 데이터를 암호화하기 위해 사용된다.
클라이언트는 CA인증서가 믿을만한지 검토하고 CA의 공개키로 이를 복호화하여 A의 공개키를 알게된다.
클라이언트는 난수 바이트를 생성하여 이를 3에서 알아낸 A의 공개키로 암호화하여 서버에게 전송한다. 서버가 이를 받아 자신의 비밀키로 이것을 복호화한다면 서로 대칭키를 안전하게 교환하였기 때문에 TLS/SSL Handshake과정 종료이다.
1~2번 과정에서 서버가 클라이언트의 인증서를 요구하는 경우가 있는데, 이 경우에는 클라이언트가 자신의 인증서, 자신의 비밀키로 암호화한 난수 바이트 문자열을 함께 보낸다.
서버는 5번의 데이터를 받고, CA기업의 공개키로 데이터를 복호화하여 클라이언트의 공개키를 알게 되고 이 공개키 (? 모르겟음 설명)
4번이 끝나면 클라이언트는 서버에게 finished 메세지를 보낸다. 이 때, 인증을 더하기 위해 서버와 교환한 모든 내역을 대칭키로 암호화하여 서버에게 보낸다.
서버는 교환 내역을 대칭키로 복호화하여 자신의 교환 내역과 일치하는 지 확인한다. 일치한다면 성공적으로 Handshake를 마친 것이기 때문에 클라이언트에게 finished 메세지를 대칭키로 암호화하여 클라이언트에게 전송한다.
클라이언트에서는 이 메세지를 받아 대칭키로 복호화한다. 복호화한 데이터가 정상이라면 이 서버와는 대칭키를 통해 통신을 할 수 있다는 것을 확신하여 서로 데이터를 주고받을 수 있게 된다.
로드 밸런서 (LB)
요즘은 웹사이트에 접속하는 인원이 매우 크게 늘어났다. 그렇기 때문에 이런 수많은 사용자들을 하나의 서버 컴퓨터에서 모두 처리하게 되면 과부하가 일어난다.
과부하를 해결하기 위한 두가지 방법은 서버의 성능을 늘리는 것(Scale-Up), 그리고 서버를 여러대 두어 트래픽을 분산시키는 것(Scale-Out)이다.
하드웨어의 성능은 하이엔드로 갈 수록 가격이 매우 크게 올라간다. 그리고 만약 서버에 문제가 생기게 될 경우에, 서버가 한대라면 웹사이트 접근이 아예 불가능해지는 문제가 있다. 그렇기 때문에 Scale-Out방식이 Scale-Up방식보다 여러 방면에서 효율적이다.
로드 밸런서는 위의 Scale-Out 방식을 사용했을 때, 여러 서버에 부하(load)를 분산시키는 '분산식 웹 서비스'이다.
로드 밸런서에 장애가 생기게 되면 분산이 불가능해진다. 그렇기 때문에 로드밸런서도 이중화 시켜 분산이 계속될 수 있도록 한다.
로드 밸런서가 서버를 선택하는 방식
Round Robin (RR)
CPU 스케쥴링에 사용되는 그 방식과 같다. 1번 요청은 1번 서버, 2번 요청은 2번 서버 이런식으로 차례로 할당하는 것이며 당연하게도 서버 사용량이 균등해진다.
Least connections
가장 부하가 적은 서버에 우선 할당시킨다.
Source
사용자의 IP를 해시한 값을 통해 서버 배정, 이 경우 같은 IP를 사용하여 접속한 사용자는 항상 같은 서버에 배정되는 것이 보장된다.
0개의 댓글